Learning Kafka and Redis with C++: A Beginners Guide
Recently, I gave a presentation about how Netflix uses the Write-Ahead Logs to ensure that they are building a resilient data platform across the hundreds of microservices and data stores that they operate every second. In delivering this presentation, I gained a solid conceptual understanding of Kafka and the many other tools that Netflix used to create a more reliable data platform, however, I am a firm believer in the idea that applying conceptual knowledge can give an individual enhanced understanding of a topic and that is what I did with my KafkaTwitterBroker project. Through this project, I created a simple program that implements many basic concepts from the presentation all in C++! This blog post will detail many of the learnings I took away from the project.
What is Kafka?
Apache Kafka is an open-source event streaming platform that is used to build many things from data pipelines to data applications and analytics. Essentially, it is a message queue that allows developers to send messages from one place to another within distributed applications and software such as microservices architecture. Any Kafka message queue is composed of three main components: A producer, a consumer, and a broker. As can be inferred from the names of the components, a producer sends the messages to the broker, the broker receives the messages and then stores them on disk, and finally the consumer pulls messages from the broker at rates determined by the engineer*.
More specifically, the consumer pulls from these things called topics. Topics are what you send data to and pull from. Examples of topics can be "stock-tick-data" or "live-scores", so you would have producers sending data to "stock-tick-data" and consumers pulling data from the very same topic. As consumers are pulling data from the topics, they are bundled into primitives called consumer "groups". For example, if different departments within a company need the same data from the "stock-tick-data", each one of them would have their own consumer group that pulls all of the data. It is important to note that each of the consumer groups pull all of the data (so each of a "Analytics" group and a "HR" group would be pulling all of the data from a "Employee-Data" topic, for example). In addition to this, within a consumer group there are the consumers that are actually pulling the data and if there are multiple consumers within a consumer group, then the consumers within the group share the work of pulling all of the data from a given topic.
In my project specifically, I used Kafka as a broker to stream generated messages to the broker through my consumer. These messages would then be polled by my consumer which is continuously pulling messages from the topic at a rate of every 3 seconds. In this way I was able to fully build a Kafka pipeline and understand how distributed message stream processors are built and used.
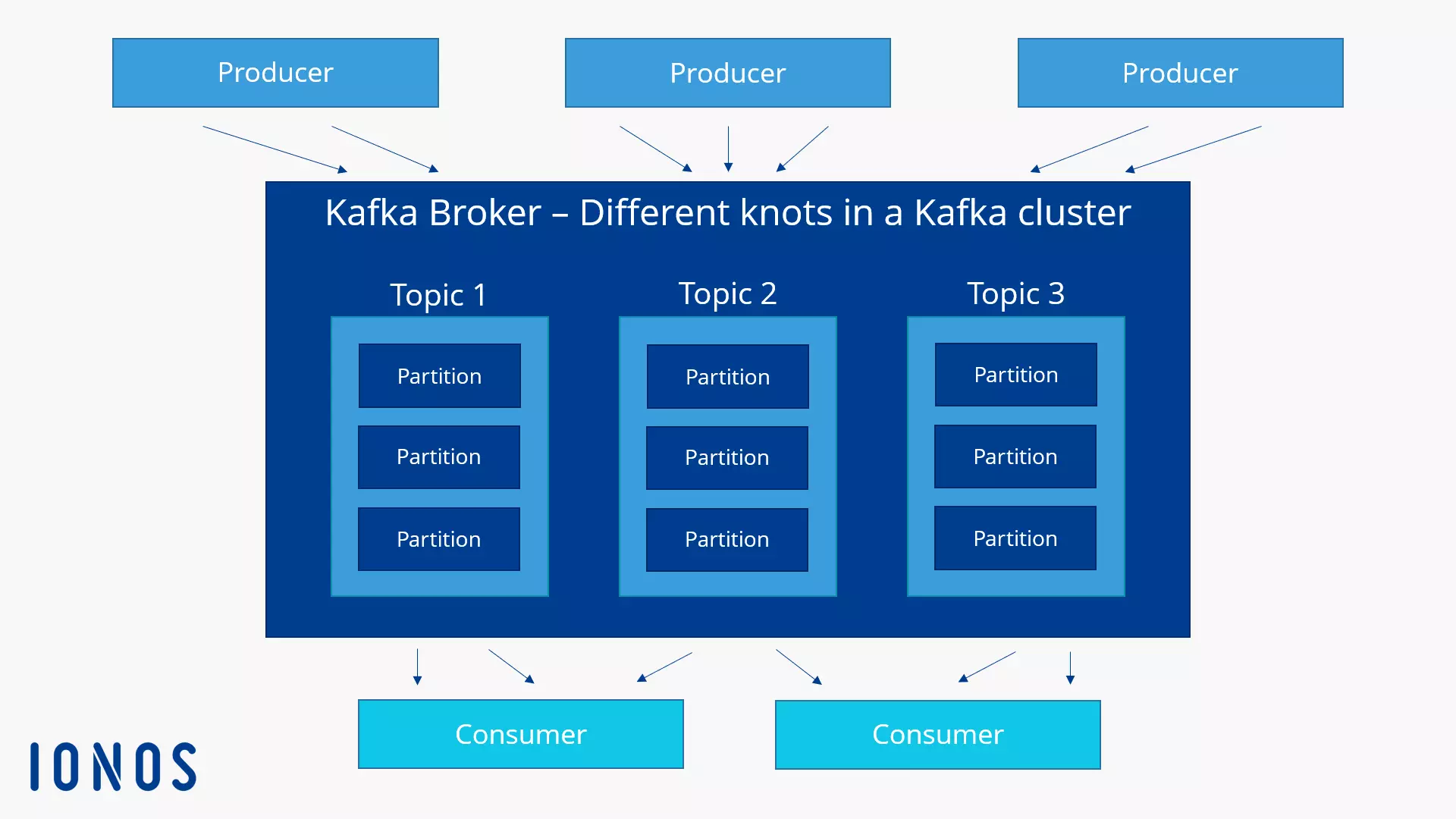
Figure 1: Diagram of a Kafka Broker (Source: IONOS)
What is Zookeeper vs KRaft?
Apache Zookeeper is an open-source distributed coordinate service. Essentially, it is one of the most commonly used distributed systems software that helps multiple servers agree on a shared configuration (source of truth), track which nodes are alive, and elect new leaders when failures occur.
In older versions of Kafka, Zookeeper was used for cluster coordination: tracking which brokers are alive, which broker leads each partition, and where consumer offsets are stored. Starting with Kafka 3.3 however, KRaft mode removes the need for Zookeeper by building this coordination directly into Kafka itself. This simplifies deployment since you only need to run Kafka as I did in the project, not a separate Zookeeper service.
What is Redis?
Redis is an in-memory data store meaning that Redis keeps all of its data in RAM unlike a traditional database that reads from disk. This makes Redis extremely fast, potentially achieving speeds of microseconds instead of milliseconds. Redis supports rich data types like strings, lists, sets, and hashes so you can do operations like "add to front of a list" or "increment a counter" directly. Memcached is another in-memory cache, but it only supports simple key-value strings and doesn't offer the support for richer data structures that Redis has. Generally, in-memory datastores like redis are used as a cache layer, sitting in between your application and a slower database to speed up frequent reads. In my project, I used Redis to store recent messages/"tweets" from the Kafka consumer, creating a fast lookup layer that the console interface could query. The key Redis commands that we used were LPUSH (add to front of a list), LTRIM (keep only the last N items), and LRANGE (get a range of items from a list).
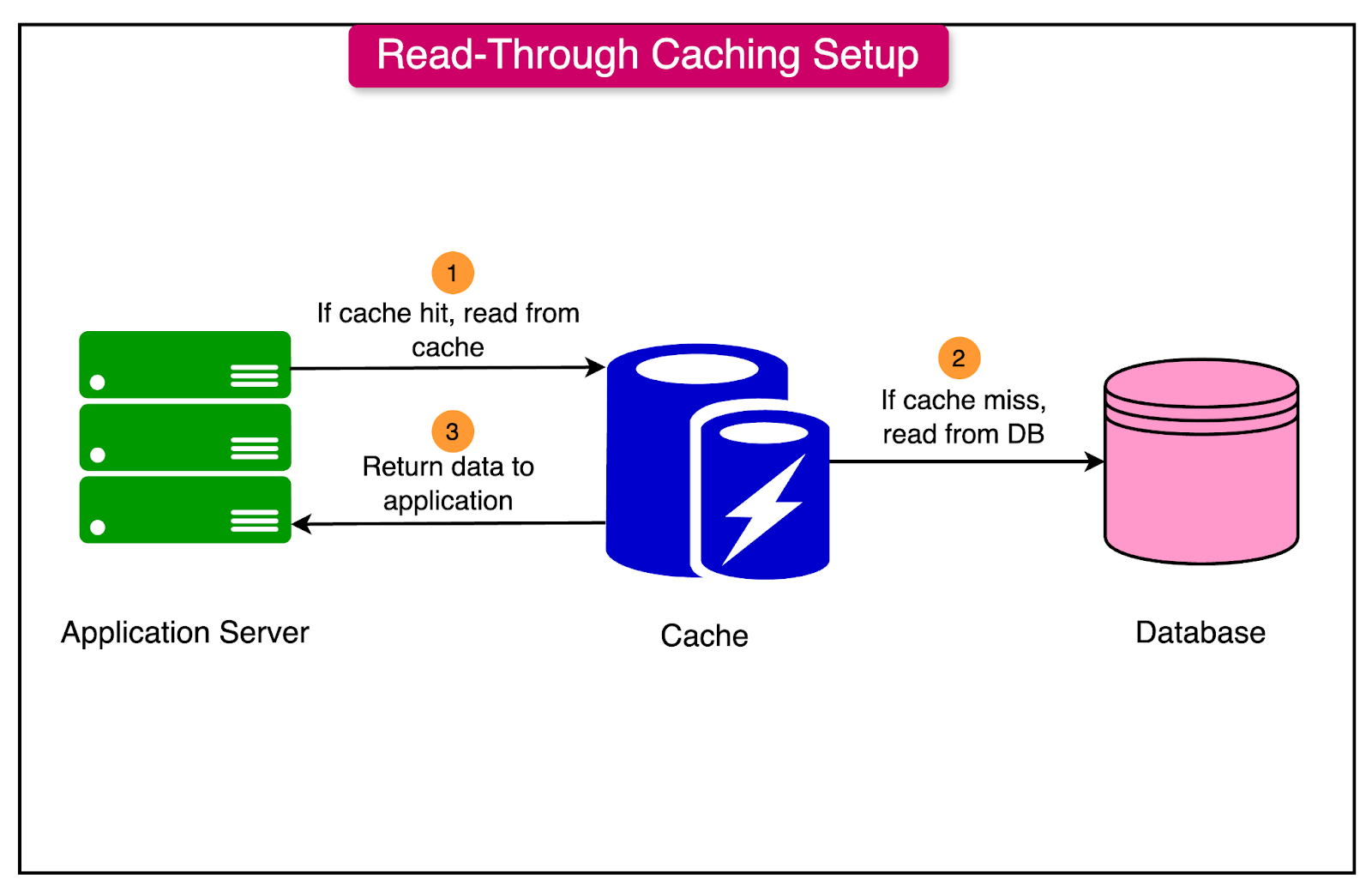
Figure 2: Diagram of Data Retrieval with a Cache (Source: ByteByteGo)
Conclusion
In conclusion, Kafka and Redis are foundational tools for building systems at massive scale. Kafka ensures reliable, high-throughput data streaming between different services, while Redis provides a fast caching mechanism to reduce latency on frequently read requests. Building this project from scratch helped me understand not just what these tools do, but why they're essential for modern distributed systems.
Project Repository: https://github.com/8SK3PS8/KafkaTweetBroker
* A common misconception is that the producer sends the messages straight to the consumer which is always waiting and ready to receive the message but that is not exactly true. Kafka, and many other message queues, have what is called a "pull-based" structure in that the consumers have to pull/poll the data instead of just having it piped to them.